
客服中心
聯(lián)系我們
- 聯(lián)系地址:廣東省廣州市天河區(qū)科新路優(yōu)可商務(wù)中心B棟3樓
- 服務(wù)熱線:400 605 3393
- 聯(lián)系電話:020-85550388 (10線) 020-85550288
- 傳真電話:020-85557779
語音識別,什么是語音識別
發(fā)表時間:2021年05月18日瀏覽量:
語音識別
與機(jī)器進(jìn)行語音交流,讓機(jī)器明白你說什么,這是人們長期以來夢寐以求的事情。語音識別技術(shù)就是讓機(jī)器通過識別和理解過程把語音信號轉(zhuǎn)變?yōu)橄鄳?yīng)的文本或命令的高技術(shù)。語音識別是一門交叉學(xué)科。近二十年來,語音識別技術(shù)取得顯著進(jìn)步,開始從實(shí)驗(yàn)室走向市場。人們預(yù)計(jì),未來10年內(nèi),語音識別技術(shù)將進(jìn)入工業(yè)、家電、通信、汽車電子、醫(yī)療、家庭服務(wù)、消費(fèi)電子產(chǎn)品等各個領(lǐng)域。
語音識別聽寫機(jī)在一些領(lǐng)域的應(yīng)用被美國新聞界評為1997年計(jì)算機(jī)發(fā)展十件大事之一。很多專家都認(rèn)為語音識別技術(shù)是2000年至2010年間信息技術(shù)領(lǐng)域十大重要的科技發(fā)展技術(shù)之一。
語音識別技術(shù)所涉及的領(lǐng)域包括:信號處理、模式識別、概率論和信息論、發(fā)聲機(jī)理和聽覺機(jī)理、人工智能等等。
通過語音控制各種設(shè)備、與電腦進(jìn)行直接的交流是人類長期以來的夢想。在許多描述未來世界的電影、小說中,語音識別幾乎成為了人工智能的代名詞。從上世紀(jì)四十年代開始,隨著數(shù)字技術(shù)尤其是電腦的飛速發(fā)展,語音識別技術(shù)成為了科學(xué)研究的熱點(diǎn)。到八十年代,語音識別技術(shù)開始了從實(shí)驗(yàn)室到產(chǎn)品的轉(zhuǎn)移。
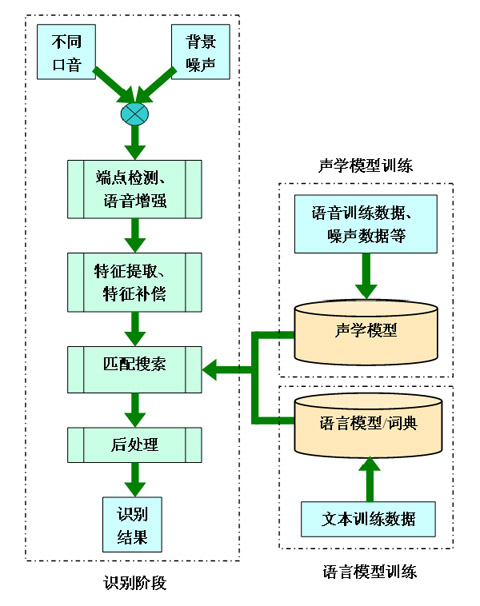
在語音識別技術(shù)領(lǐng)域的研發(fā),開始于上世紀(jì)七十年代,目前已經(jīng)形成了以東京-劍橋-北京為中心的全球研發(fā)體系,開發(fā)出了包括中、日、英、法、德等十四種以上語言的語音識別系統(tǒng)。中國研發(fā)中心,從二零零一年成立以來,致力于中文(包含粵語及各種方言)語音識別技術(shù)的研發(fā),開發(fā)了高性能的中文語音識別引擎,如下圖所示:
我們的語音識別技術(shù)支持不同層次的系統(tǒng)要求:
1. 高魯棒性嵌入式語音識別引擎,可以應(yīng)用到各種電子設(shè)備,從而利用語音來完成電子設(shè)備的自動控制等。特別在車載環(huán)境下,利用語音來控制各種設(shè)備的"hand-free"模式已經(jīng)成為語音識別技術(shù)最重要的應(yīng)用之一。
嵌入式語音識別引擎結(jié)合了高性能語音端點(diǎn)檢測技術(shù)、語音增強(qiáng)技術(shù)和特征補(bǔ)償技術(shù),并采用了噪聲免疫訓(xùn)練,可以在各種噪聲環(huán)境下工作;特別針對汽車背景噪聲優(yōu)化,在極低信噪比環(huán)境下仍可使用。該引擎無需特別訓(xùn)練即可供不同說話人使用,并特別針對不同地方口音進(jìn)行優(yōu)化,可以同時支持不同口音的說話人。除了可以完成高精度的命令詞識別,東芝的嵌入式語音識別引擎支持大詞匯量的地址識別,結(jié)合在線文法生成功能和語音標(biāo)簽功能,使得聲控的汽車導(dǎo)航成為現(xiàn)實(shí)。此外,該引擎還支持中文數(shù)字串識別和人名識別等,可以輕松完成聲控?fù)芴?定位任務(wù)。引擎采用了高效的搜索算法和聲學(xué)模型壓縮等技術(shù),可以在資源十分有限的條件下工作,目前已經(jīng)應(yīng)用到多款汽車導(dǎo)航系統(tǒng)中。
2. 語音對話系統(tǒng)和翻譯系統(tǒng)中的語音聽寫引擎。結(jié)合語音識別/合成和機(jī)器翻譯技術(shù),不同語言間的自動語音翻譯已經(jīng)成為可能。
語音翻譯系統(tǒng),目前已經(jīng)支持中、英、日三國語言的互譯。作為其中重要的模塊之一,我們開發(fā)了高性能的中文語音聽寫引擎(大詞表連續(xù)語音識別系統(tǒng))。該系統(tǒng)采用了噪聲魯棒性技術(shù),可以應(yīng)用到不同環(huán)境中。聲學(xué)模型訓(xùn)練中采用了區(qū)分性訓(xùn)練,并針對不同地方口音進(jìn)行了優(yōu)化;高性能的自適應(yīng)技術(shù),可以在無監(jiān)督的模式下有效提高對不同口音和環(huán)境的適應(yīng)能力。該引擎支持大詞匯量的語音聽寫,并提供了用戶詞典功能;具有高可移植性,可以為不同領(lǐng)域快速定制識別引擎。
常用的一些聲學(xué)特征
* 線性預(yù)測系數(shù)LPC:線性預(yù)測分析從人的發(fā)聲機(jī)理入手,通過對聲道的短管級聯(lián)模型的研究,認(rèn)為系統(tǒng)的傳遞函數(shù)符合全極點(diǎn)數(shù)字濾波器的形式,從而n 時刻的信號可以用前若干時刻的信號的線性組合來估計(jì)。通過使實(shí)際語音的采樣值和線性預(yù)測采樣值之間達(dá)到均方差最小LMS,即可得到線性預(yù)測系數(shù)LPC。對 LPC的計(jì)算方法有自相關(guān)法(德賓Durbin法)、協(xié)方差法、格型法等等。計(jì)算上的快速有效保證了這一聲學(xué)特征的廣泛使用。與LPC這種預(yù)測參數(shù)模型類似的聲學(xué)特征還有線譜對LSP、反射系數(shù)等等。
* 倒譜系數(shù)CEP:利用同態(tài)處理方法,對語音信號求離散傅立葉變換DFT后取對數(shù),再求反變換iDFT就可得到倒譜系數(shù)。對LPC倒譜(LPCCEP),在獲得濾波器的線性預(yù)測系數(shù)后,可以用一個遞推公式計(jì)算得出。實(shí)驗(yàn)表明,使用倒譜可以提高特征參數(shù)的穩(wěn)定性。
* Mel倒譜系數(shù)MFCC和感知線性預(yù)測PLP:不同于LPC等通過對人的發(fā)聲機(jī)理的研究而得到的聲學(xué)特征,Mel倒譜系數(shù)MFCC和感知線性預(yù)測 PLP是受人的聽覺系統(tǒng)研究成果推動而導(dǎo)出的聲學(xué)特征。對人的聽覺機(jī)理的研究發(fā)現(xiàn),當(dāng)兩個頻率相近的音調(diào)同時發(fā)出時,人只能聽到一個音調(diào)。臨界帶寬指的就是這樣一種令人的主觀感覺發(fā)生突變的帶寬邊界,當(dāng)兩個音調(diào)的頻率差小于臨界帶寬時,人就會把兩個音調(diào)聽成一個,這稱之為屏蔽效應(yīng)。Mel刻度是對這一臨界帶寬的度量方法之一。
MFCC的計(jì)算首先用FFT將時域信號轉(zhuǎn)化成頻域,之后對其對數(shù)能量譜用依照Mel刻度分布的三角濾波器組進(jìn)行卷積,最后對各個濾波器的輸出構(gòu)成的向量進(jìn)行離散余弦變換DCT,取前N個系數(shù)。PLP仍用德賓法去計(jì)算LPC參數(shù),但在計(jì)算自相關(guān)參數(shù)時用的也是對聽覺激勵的對數(shù)能量譜進(jìn)行DCT的方法。
語音識別系統(tǒng)的性能指標(biāo)主要有四項(xiàng)。①詞匯表范圍:這是指機(jī)器能識別的單詞或詞組的范圍,如不作任何限制,則可認(rèn)為詞匯表范圍是無限的。②說話人限制:是僅能識別指定發(fā)話者的語音,還是對任何發(fā)話人的語音都能識別。③訓(xùn)練要求:使用前要不要訓(xùn)練,即是否讓機(jī)器先“聽”一下給定的語音,以及訓(xùn)練次數(shù)的多少。④正確識別率:平均正確識別的百分?jǐn)?shù),它與前面三個指標(biāo)有關(guān)。
小結(jié)
以上介紹了實(shí)現(xiàn)語音識別系統(tǒng)的各個方面的技術(shù)。這些技術(shù)在實(shí)際使用中達(dá)到了較好的效果,但如何克服影響語音的各種因素還需要更深入地分析。目前聽寫機(jī)系統(tǒng)還不能完全實(shí)用化以取代鍵盤的輸入,但識別技術(shù)的成熟同時推動了更高層次的語音理解技術(shù)的研究。由于英語與漢語有著不同的特點(diǎn),針對英語提出的技術(shù)在漢語中如何使用也是一個重要的研究課題,而四聲等漢語本身特有的問題也有待解決。
端")


號")

